
Machine-Learning-Modelle im dynamischen Umfeld
Die Bedeutung von Künstlicher Intelligenz in der Versicherungsbranche hat in den vergangenen Jahren zunehmend an Bedeutung gewonnen. Allerdings neigen Modelle für maschinelles Lernen (ML), die sich in einem sich verändernden Datenumfeld bewegen, dazu, im Laufe der Zeit ihre Qualität zu verlieren.
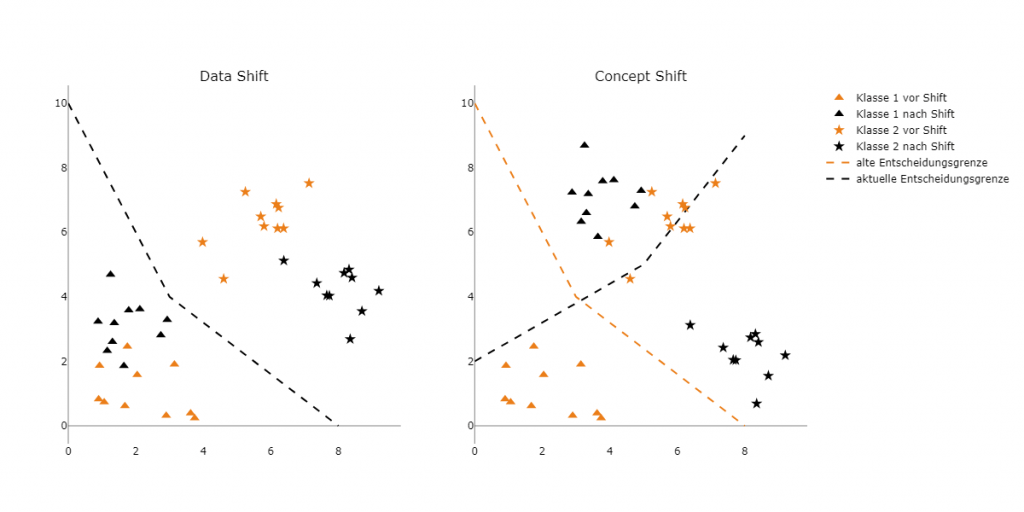
Data Shift und Concept Shift
Ein wichtiger Faktor, der zu einer Verschlechterung der Vorhersagequalität von Modellen beitragen kann, sind Verschiebungen in den Inputdaten, auch als Shifts bezeichnet. Zwei Kategorien sind der Data Shift und der Concept Shift. Der Data Shift ist eine Veränderung innerhalb der Verteilung der Werte (Features) im Input gegenüber derjenigen, mit der das Modell trainiert wurde (die Baseline). Zum Beispiel wurden ML-Modelle, die das Konsumverhalten als Eingabe verwendeten, durch die COVID-19-Pandemie beeinflusst, als es zu einem plötzlichen Wechsel zum Online-Shopping kam. Im Gegensatz dazu bezeichnet ein Concept Shift die Veränderung der funktionalen Zusammenhänge zwischen dem Input und dem Output eines Modells, die dazu führt, dass die durch das Modell erlernten Entscheidungsgrenzen ihre Gültigkeit verlieren. Symptome einer Atemwegserkrankung bedeuteten etwa vor der Pandemie ein geringes Risiko für eine Krankenhauseinweisung, während sie auf dem Höhepunkt der Pandemie ein deutlich höheres Risiko darstellten.
Modellqualität
Daher ist neben der gründlichen Validierung der Modellqualität vor Einsatz der Modelle auch eine Überwachung der Modellqualität im Verlauf des Einsatzes unerlässlich.
Zur Bewertung von Klassifikationsmodellen werden häufig die Confusion Matrix und Metriken, wie beispielsweise der F1-Score verwendet. Diese Metriken haben gemeinsam, dass für ihre Anwendung neben den Vorhersagen des Modells auch die tatsächlich eingetretenen Ergebnisse (Ground Truth) bekannt sein müssen.
Modellmonitoring
Um mit diesem Problem umzugehen, lassen sich zwei Arten von Methodiken unterscheiden: Univariate, welche einzelne Features für sich betrachten, und Covariate-Monitoring-Methoden, die die Kreuzwirkungen von Merkmalen betrachten.
Bei einer univariaten Verteilungsanalyse werden Verteilungen der einzelnen Merkmale untersucht und statistisch mit den Modellentwicklungsdaten verglichen. Auf diese Weise kann geprüft werden, ob sich die Verteilung eines Features signifikant von der Referenz unterscheidet. Ein solches Vorgehen ermöglicht die Beobachtung von Veränderungen und Trends in den Daten.
Eine Aussage darüber, ob Datenveränderungen eine statistisch signifikante Auswirkung auf die Modellqualität besitzen, kann mit dieser Information allein allerdings nicht getroffen werden.
Zur Beleuchtung dieses Aspekts kann ein Ansatz herangezogen werden, der darauf abzielt, gewisse Klassifikationsmetriken (wie den F1-Score) vorherzusagen, ohne dabei die tatsächliche Ground Truth zu kennen. Dieses Verfahren nutzt die Confidence Scores, die in den meisten gängigen Klassifikationsalgorithmen enthalten sind.
Es basiert allerdings auf dem durch das Modell gelernten Verhalten der Daten, was die Ergebnisse anfällig gegenüber Concept Shifts und Covariate Shifts macht.
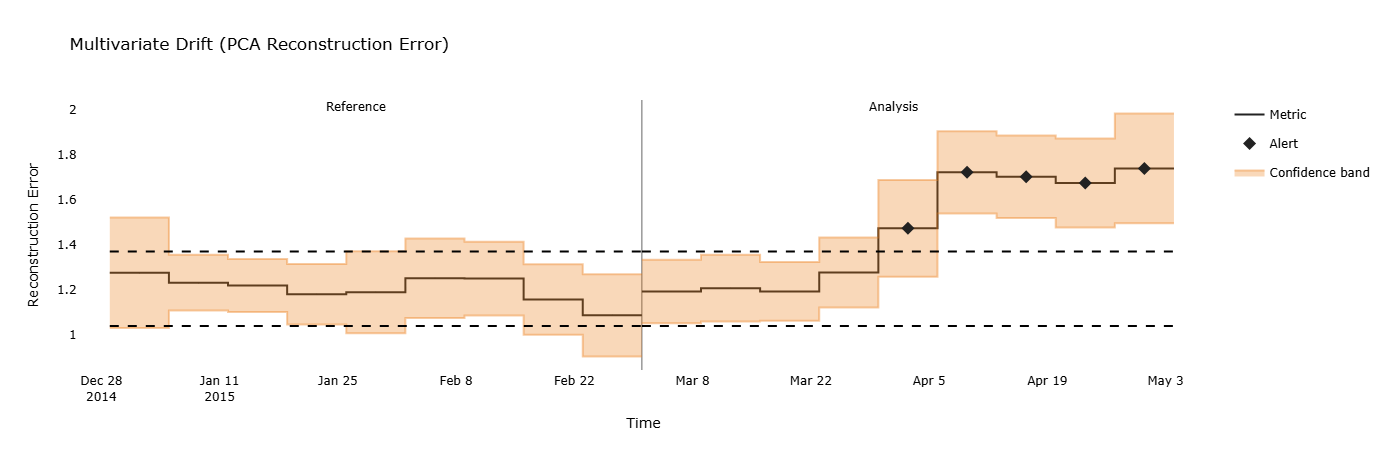
Die beiden zuvor besprochenen Verfahren ermöglichen das Detektieren von statistisch signifikanten Veränderungen sowie die Schätzung von Klassifikationsmetriken. Beide Verfahren können allerdings Schwächen bei Covariate Shifts sowie Concept Shifts aufweisen. Ein Vorgehen, das in der Lage ist, solche komplexeren Veränderungen in den Daten zu detektieren, nutzt Machine-Learning-Techniken, um das Verhalten der Daten zu „lernen“ und mit dem Verhalten der neu hinzukommenden Daten zu vergleichen. Auf diese Art lassen sich auch komplexe Veränderungen in den Ausgangsdaten detektierbar machen.
Wollen Sie mehr über Modellmonitoring erfahren?
Einen tieferen Einblick in Modellmonitoring-Techniken stellen wir in unserem Whitepaper “Überwachung von Machine-Learning Models im laufenden Betrieb” vor. Dieses kann unter der Adresse info@vtmw.de angefragt werden.
Sie möchten mehr erfahren? Rufen Sie uns gerne unter +49 (0)6431 – 496658 – 0 an.